




Later this year, the US Supreme Court will rule on a case with profound implications for society and technology. The case centres on Nohemi Gonzalez, a US student who in 2015 was shot and killed by the Islamist terrorist group ISIS in Paris. Her father claims in the suit that Google, which owns the video platform YouTube, should be held responsible for permitting the platform’s recommender algorithms to promote content that radicalized the terrorists who killed Gonzalez. The final ruling, expected by the end of June, could make digital platforms liable for their algorithms’ recommendations.
Whatever decision the court makes, the case highlights an urgent question: how can societies govern adaptive algorithms that continually change in response to people’s behaviour? YouTube’s algorithms, which recommend videos through the actions of billions of users, could have shown viewers terrorist videos on the basis of a combination of people’s past behaviour, overlapping viewing patterns and popularity trends. Years of peer-reviewed research shows that algorithms used by YouTube and other platforms have recommended problematic content to users even if they never sought it out1. Technologists struggle to prevent this.
Adaptive algorithms that react to collective action have been linked to other wide-ranging effects. During the 2010 stock market crash, adaptive algorithms responded to a mass stock sell-off initiated by humans and helped it to spiral out of control2. An adaptive algorithm that recommended new connections on the professional social network LinkedIn played a part in helping hundreds of thousands of people to move jobs3. Generative artificial-intelligence (AI) programs in chatbots have adapted to human behaviour in ways that include learning to parrot racist hate speech. As AI systems are deployed even more widely, the lives of people and adaptive algorithms will become increasingly intertwined.
To regulate such algorithms and ensure a safe, beneficial role for them in society, researchers must build knowledge in science and engineering on collective patterns of human–algorithm behaviour. They need to classify, explain and forecast these patterns, as well as develop interventions that can prevent problems. This will require academics to break down disciplinary boundaries, develop new methods and work collaboratively with communities affected by algorithms. Here, I lay out four steps to develop this science.
A complex system
An adaptive algorithm is any software that regularly updates its own behaviour based on outcomes that it also influences. The underlying mathematical principles of such algorithms can vary, from simple correlation to deep learning4. Many systems are ensembles of multiple models combined into a unified output, such as a video suggestion or a stock trade. When humans respond to those outputs, adaptive algorithms update their own behaviour in turn.
The resulting feedback loop of human–algorithm behaviour is a complex system, in which multiple actors adapt in response to each other and small changes in one part of the system, such as an algorithm adjustment, can lead to unexpected consequences or even collapse. When YouTube’s algorithms suggest terrorist recruitment videos, they are responding to collective audience behaviour, as well as campaigns from terrorist groups and counter-campaigns from governments and civil society1,5.
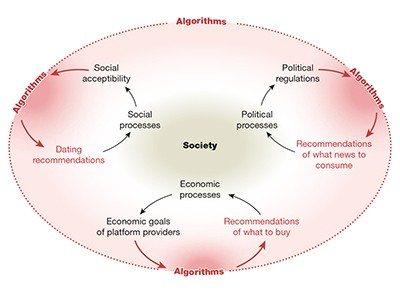
Measuring algorithmically infused societies
Few patterns of human–algorithm behaviour are exclusively good or bad for society. When YouTube connected some viewers to content posted by members of terrorist groups, its algorithms might have contributed to clustering — a term for identifying and connecting people who have similar tastes in news or culture, whether or not they previously viewed such videos6. These links were suggested to a small proportion of the platform’s users at the time — more than one billion in 2015. Similar clustering patterns have brought together influential social movements, given people access to new employment networks and connected people with similar medical conditions to organize the search for cures. A blanket ban on clustering algorithms could reduce these public goods and threaten basic human rights, such as the freedom of association.
This scientific and moral thicket makes it difficult for technologists to safety-test algorithms before their release, to forecast problems, to predict the effects of software changes or to achieve a stable state7. The scientific uncertainty has also created questions about who bears responsibility. “It takes two to tango,” wrote Nick Clegg, president of global affairs at the social-media company Meta, arguing that because the company’s algorithms respond to unpredictable human behaviour, companies should be held less responsible for the outcomes. Industry advocates — those not directly involved in the case but who have a strong interest in its outcome — have filed many ‘amicus briefs’ in Gonzalez v. Google, arguing a similar point. In oral arguments in the case, Google’s legal counsel argued that the company should legally be protected from liability whether or not its recommender algorithms were biased in favour of videos by terrorist recruiters (see go.nature.com/3hvcimz).
Scientists and technology firms have built relationships to study algorithms and society8. In 2018, for example, Facebook (now known as Meta) established initiatives, such as Social Science One, to share data with academic researchers studying the impact of the platform on democratic elections. But academics have also raised concerns that firms sometimes obstruct research. In 2021, Meta cut off data access to researchers at New York University after the academics discovered systematic gaps in transparency data that Meta was providing to academics and regulators about posts before and after the 6 January US Capitol Hill riots. Meta said that it fixed the error. As co-founder of the Coalition for Independent Technology Research, a non-profit organization, I help to defend the right to study the impact of technology on society.
Because companies struggle to control algorithms directly, governments have pressured tech firms to police human behaviour. In 2021, the European Union introduced regulation requiring companies to monitor and remove terrorist content within one hour. Social-media platforms now employ large teams of workers to monitor the activities of billions of people to stop algorithmic harms by moderating problematic content9.
YouTube says that violent extremist groups and criminal organizations are prohibited from using the platform, and that it is committed to removing this content (see go.nature.com/44aakry). It says that YouTube recommendations generally reflect users’ personal preferences and online habits, and that recommendations actively discourage users from viewing radicalizing content by favouring mainstream, authoritative sources.
Policing everyone, everywhere, all at once is costly, laborious and error-prone. Content moderators make frequent mistakes that restrict legitimate rights, while corporate moderation policies are opaque and rarely open to appeal9. Furthermore, there is no independently verifiable evidence to support corporate claims that this digital policing keeps anyone safer. But policing people rather than algorithms will remain the status quo in algorithm governance — until advances in science enable reliable, verifiable interventions to be found.
Classify patterns of behaviour
Because adaptive algorithms are so recent, researchers and policymakers lack clear, shared language to describe how they interact with humans. Just as meteorologists classify different kinds of storm, researchers need to reliably detect and describe patterns of behaviour involving algorithms and humans in ways that scientists and the public can understand.
Relatives of Nohemi Gonzalez, who died in the 2015 Paris terror attacks, have begun a US Supreme Court case against YouTube’s owner Google.Credit: Shawn Thew/EPA-EFE/Shutterstock
Decades of interpretive research from journalists, activists and academics has started to describe recurring algorithm-involved incidents2 but they lack the precision required. For example, polarization, radicalization and organization of social movements all involve clustering, but a more detailed classification system would identify both the algorithm designs and the social forces involved — such as homophily, a human tendency to associate with people who are similar to ourselves. Classifications would also differentiate clustering from algorithm-involved patterns that drive people apart. Because harms involving algorithms are often noticed first by journalists and members of the public, these groups need to be included in such research.
To build this classification system, researchers need a shared resource of cases and evidence. Technologists have already begun to collect cases in the AI Incident Database, a log of harms or near harms involving AI systems, based mostly on journalism. But companies worried about lawsuits might refuse to provide useful forensic information when problems occur. Researchers therefore need to work together with the media, affected communities and algorithm designers to collect more systematic and detailed data on harmful and beneficial incidents alike.
Explain how human–algorithm behaviour emerges
Governance of algorithms will require reliable explanations for how things could go wrong. But neither technologists nor social scientists have the language or models to create these explanations.
To a technologist, an explanation is an account of why an algorithm took a specific action, compared with what it might have done otherwise. In the case of YouTube, computer scientists might be able to explain what part of a mathematical matrix contributed most to the algorithm’s recommendation of a terrorist video at one moment. But they aren’t easily able to suggest changes that would have prevented terrorist recruitment, because that would require a better understanding of human behaviour. That’s why computer scientists cannot say in advance whether a given design will become more harmful or less harmful over time10.
Humanities researchers and social scientists, meanwhile, are working to develop algorithm-informed explanations of collective behaviour. A 2021 study of Twitter users showed that posts expressing moral outrage received more likes than did posts showing other emotions, and that this feedback caused people to express more outrage in the future11. But studies such as this can’t currently explain how algorithms respond or what they contribute to these dynamics7.

Everyone should decide how their digital data are used — not just tech companies
One way forward comes from outside academia. When lawyers for the Gonzalez family appealed to the Supreme Court to look into the daughter’s death, the most compelling evidence on the outcomes of YouTube’s algorithm came from a crowdsourced investigation called YouTube Regrets. In the project, run by the non-profit Mozilla Foundation in San Francisco, California, and unrelated to the Paris attacks, more than 37,000 volunteers monitored what YouTube suggested to them and flagged the videos that they regretted having seen in their feed for being inaccurate, offensive and violent. By combining volunteers’ reports, researchers were able to show that the platform was recommending thousands of videos that viewers considered problematic12. The project did not look specifically at content on terrorism. YouTube says it offers viewers control over their recommendations, including the ability to block videos or channels, and that it welcomes research on its platform.
Because many adaptive algorithms present a different experience to each person, research should study those interactions en masse. In 2022, Northeastern University in Boston, Massachusetts, launched the National Internet Observatory to record and study human and algorithm behaviour in everyday life. The observatory, which has received US$15.7 million in funding from the US National Science Foundation, is recruiting tens of thousands of people to install software that monitors what algorithms are doing, and securely archives those records with people’s consent. Participants will also answer regular survey questions about their lives. As one of the observatory’s science advisers, I think it will provide crucial data across disciplines to explain how and why algorithms behave the way they do.
More collective endeavours such as this are needed. Researchers need collaborations, observatories and experiments that combine diverse human experiences with computational methods. Academics and communities need to collaborate to identify circumstances in which runaway, damaging feedback loops arise. Funders need to support such interdisciplinary studies — and journals need to publish them.
Reliably forecast and intervene
Progress towards flourishing digital environments will ultimately depend on successfully providing benefits and preventing harms. This has two parts: forecasting what could happen, and intervening effectively.
Technologists and economists have already developed software to simulate interactions between populations of people and recommendation algorithms. Simulations could some day enable designers to explore possible outcomes of changes in algorithm design13. These simulations could be improved with citizen science information from projects such as YouTube Regrets and the National Internet Observatory. As with weather models, these simulations would ultimately be evaluated on the basis of how well they forecast events outside the laboratory.
Researchers can also forecast collective harms by monitoring algorithms in real time. Over the past few years, my lab has worked together with online communities of millions of people to identify patterns in algorithm behaviour that occur before, and might predict, incoming waves of harassment. We are now analysing results from an experiment that uses these forecasts to allocate messages that studies have shown can reduce and prevent online harassment14.

The powers and perils of using digital data to understand human behaviour
Although forecasts might help people to avoid problems, the most useful research will identify effective, reliable and reproducible interventions to prevent harm. How should technologists redesign their software? What effects can we expect from certain policies? And can the public confidently organize for change? In 2022, YouTube Regrets ran a randomized trial, involving more than 20,000 people, to test the effects of a new ‘Stop recommending’ button on the platform. Using machine learning to analyse 500 million video recommendations, the group found that YouTube’s controls reduced unwanted recommendations by 11–43%, but that the platform kept recommending substantial quantities of unwanted content anyway15.
To develop the science of algorithm and human behaviour, the diversity of who does research must broaden. Because adaptive algorithms behave differently for different people, researchers in dominant cultures are often unaware of harms that affect marginalized communities. In 2021, only 19 computer-science PhDs were awarded to Black or African American scholars in the United States and Canada, out of 1,493 PhDs in total. Only 24 identified as Hispanic like me. These monocultures help to explain why activists, journalists and interpretive scholars (such as ethnographers) in more diverse fields have been so effective at observing harms that technologists failed to anticipate. Scientific funders should prioritize community and citizen-science projects that involve the public. Research collaborations should include disciplines in the social sciences and humanities that have developed broad understandings of diverse human experience. In the long term, researchers must work to diversify their institutions.
Cultivate hybrids of science and engineering
The biggest question facing the science of human–algorithm behaviour is whether science can be done at all. Critics might argue that establishing a reliable, replicable knowledge base is not possible in a system that responds differently in new situations.
To many computer scientists, human behaviour is too unpredictable to provide reliable guidance on whether interventions will work10. Social scientists worry that, because software code is frequently changed, new discoveries could be invalidated as soon as companies change an algorithm’s underlying code2.
Ironically, the persistence of algorithmic harms is the best reason to hope that they can be understood. A 2022 study of six of the most popular search engines (Google, Bing, Yahoo, Baidu, Yandex and DuckDuckGo) found that in searches for images of migrant population groups, all six tended to amplify prejudiced and dehumanizing material16. One reason algorithms are curiously predictable is that their creators are so similar. Algorithm makers operate in similar legal environments, face similar economic conditions, receive similar training and use similar data sets17. The recurrence of algorithmic harms across many systems and situations could make them classifiable and preventable.
Companies have strong incentives to resist studies that could suggest they are responsible for harms involving their products. That’s why future studies will depend on innovations in adversarial data access, ethics and privacy. Researchers should prioritize methods that don’t rely on companies, while supporting laws to require algorithm makers to collaborate with researchers. The European Union has recently agreed to mandate research access to tech-company data (see go.nature.com/4kvjdrd), and US lawmakers are considering the same.
Next steps
Creating this science of human–algorithm behaviour is a 10- to 20-year challenge. Researchers should form a long-term community of enquiry that spans disciplines and involves ongoing participation from the public. To start, the community should identify and propose initiatives for information-sharing and collaboration, both with and without participation from companies. It should also collectively envision and manage the creation of privacy-protecting research infrastructures. These scientific instruments could integrate work on classifying and explaining human–algorithm behaviour with innovations in forecasting and testing interventions.
I think that adaptive algorithms can deliver widespread benefits to society, and that their harms will some day become manageable. That can only happen if algorithms are designed and governed with reliable research. A science of human–algorithm behaviour can’t bring Nohemi Gonzalez back, but whatever the Supreme Court decides later this year, the Gonzalez family’s case against tech firms should spur science and society to act.
More News
Emx2 underlies the development and evolution of marsupial gliding membranes – Nature
High-performance fibre battery with polymer gel electrolyte – Nature
Antisense oligonucleotide therapeutic approach for Timothy syndrome – Nature